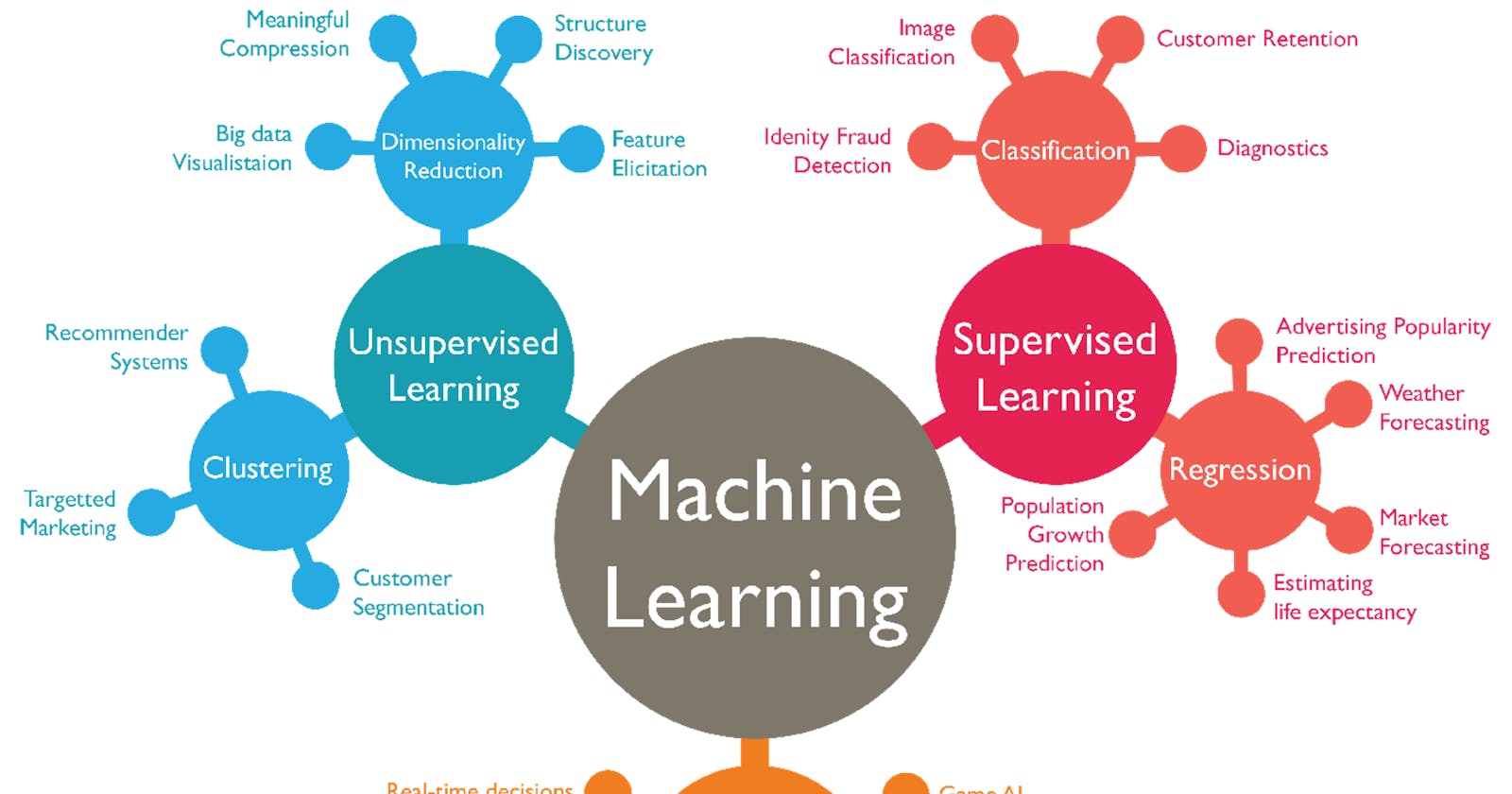


Supervised Learning Algorithms:
Supervised learning is a fundamental branch of machine learning where algorithms are trained on labeled data to make predictions or classifications.
Linear Regression: Predicts a continuous output variable based on linear relationships between input features.
Logistic Regression: Classifies input data into discrete categories using a logistic function to model the probabilities.
Decision Trees: Constructs a tree-like model by splitting data based on features to make decisions or predictions.
Random Forests: Ensemble method that combines multiple decision trees to improve prediction accuracy and reduce overfitting.
Support Vector Machines (SVM): Separates data into different classes by finding an optimal hyperplane in a high-dimensional space.
Naive Bayes: Uses Bayes' theorem and assumes independence between features to classify data based on probability calculations.
k-Nearest Neighbors (k-NN): Classifies data based on the majority vote of its k nearest neighbors in the feature space.
Gradient Boosting algorithms: Ensemble methods that sequentially build weak models, minimizing the errors of previous models to improve predictions.
Unsupervised Learning Algorithms:
Unsupervised learning is a branch of machine learning where algorithms analyze and explore data without labeled output. Instead of predicting specific outcomes, unsupervised learning algorithms aim to identify patterns, structures, or relationships within the data.
K-means Clustering: Divides data into k clusters based on similarity, aiming to minimize the intra-cluster variance.
Hierarchical Clustering: Builds a hierarchy of clusters by iteratively merging or splitting them based on similarity.
DBSCAN: Density-based clustering algorithm that groups together data points in high-density regions while marking outliers as noise.
Gaussian Mixture Models (GMM): Models data as a combination of Gaussian distributions to perform probabilistic clustering.
Principal Component Analysis (PCA): Reduces the dimensionality of data by transforming it into a new set of uncorrelated variables called principal components.
t-Distributed Stochastic Neighbor Embedding (t-SNE): Dimensionality reduction technique that visualizes high-dimensional data in a lower-dimensional space, emphasizing local structure.
Reinforcement Learning Algorithms:
Reinforcement Learning (RL) algorithms focus on training agents to make sequential decisions in an environment to maximize cumulative rewards. The agent interacts with the environment, takes actions, receives feedback (rewards), and learns from this experience.
Q-Learning: Reinforcement learning algorithm that learns through trial and error, optimizing actions based on maximizing cumulative rewards.
Deep Q-Network (DQN): Reinforcement learning algorithm that combines Q-learning with deep neural networks for improved performance in complex environments.
Proximal Policy Optimization (PPO): Policy optimization algorithm that iteratively updates policies to maximize rewards and improve sample efficiency.
Monte Carlo Tree Search (MCTS): Search algorithm that simulates and evaluates possible moves in a game tree to determine optimal actions.
Actor-Critic Methods: Reinforcement learning approach that combines a policy network (actor) and a value function (critic) to guide learning.
Deep Learning Algorithms:
Deep Learning is a subset of machine learning that involves training artificial neural networks with multiple layers (deep architectures) to learn patterns and representations from data. These algorithms have demonstrated exceptional performance in various tasks and have revolutionized fields like computer vision, natural language processing, and speech recognition.
Convolutional Neural Networks (CNN): Deep learning models designed for image processing, using convolutional layers to extract meaningful features.
Recurrent Neural Networks (RNN): Neural networks that can process sequential data by retaining and using information from previous inputs.
Long Short-Term Memory_(LSTM): A type of RNN that addresses the vanishing gradient problem and can retain information over longer sequences.
Generative Adversarial Networks (GAN): Neural network architecture consisting of a generator and a discriminator, trained in competition to produce realistic data.
Transformer Networks: Architecture that employs self-attention mechanisms to process sequences, widely used in natural language processing tasks.
Autoencoders: Neural networks designed to learn compressed representations of input data by training to reconstruct the original input from a reduced-dimensional representation.
Semi-Supervised Learning Algorithms:
Semi-supervised learning is a type of machine learning where a model is trained using a combination of labeled and unlabeled data. This approach leverages the benefits of both supervised learning (using labeled data) and unsupervised learning (using unlabeled data) to improve the model's performance.
Expectation-Maximization (EM): Iteratively estimates the parameters of a probabilistic model by alternately computing expected values and maximizing likelihood.
Self-Training: Uses a small amount of labeled data to train a model, which is then used to label a larger amount of unlabeled data for further training iterations.
Co-Training: Simultaneously trains multiple models on different subsets of features or data instances, leveraging their agreement on the unlabeled data.
Label Propagation: Propagates labels from labeled instances to unlabeled instances based on their similarity, utilizing the local structure of the data.
Generative Models with Labeled and Unlabeled Data: Combines generative models with both labeled and unlabeled data to estimate class distributions and make predictions.
Ensemble Learning Algorithms:
Ensemble learning is a powerful machine learning technique that combines multiple models to improve overall performance and generalization. By aggregating the predictions of diverse models, ensemble methods can often achieve higher accuracy and robustness compared to individual models.
Bagging: Ensemble technique that combines multiple models trained on different subsets of the training data to make predictions.
Boosting: Ensemble method that combines weak learners sequentially, with each subsequent model focusing on instances that previous models struggled with.
Stacking: Ensemble approach that combines predictions from multiple models by training a meta-model on their outputs.
Voting Classifiers: Ensemble method that combines predictions from multiple models by majority voting or weighted voting.
Dimensionality Reduction Algorithms:
Dimensionality reduction is a set of techniques used to reduce the number of features or variables in a dataset while preserving its essential information. These algorithms are beneficial for visualizing high-dimensional data, reducing computation time, and improving the performance of machine learning models.
Principal Component Analysis (PCA): Reduces the dimensionality of data by transforming it into a new set of uncorrelated variables called principal components.
Linear Discriminant Analysis (LDA): Maximizes class separability by finding linear combinations of features that best discriminate between classes.
t-Distributed Stochastic Neighbor Embedding (t-SNE): Dimensionality reduction technique that visualizes high-dimensional data in a lower-dimensional space, emphasizing local structure.
Independent Component Analysis (ICA): Separates a multivariate signal into additive subcomponents to discover underlying independent sources.
Variational Autoencoders (VAE): Neural network-based generative models that learn low-dimensional representations and reconstruct original data with high fidelity.
Transfer Learning Algorithms:
Transfer learning is a machine learning technique that leverages knowledge gained from one task or domain to improve performance on another related task or domain. Instead of training a model from scratch, transfer learning adapts an existing pre-trained model by fine-tuning or using its learned features.
Pre-trained Deep Neural Networks: Deep learning models that are trained on large-scale datasets for specific tasks, are often used as a starting point for transfer learning.
Fine-tuning: Technique where a pre-trained model is further trained on a specific task or dataset to improve its performance.
Domain Adaptation: Technique that transfers knowledge from a source domain to a target domain with different distributions, improving generalization.
Multi-task Learning: Simultaneously trains a model on multiple related tasks to improve overall performance by leveraging shared information.