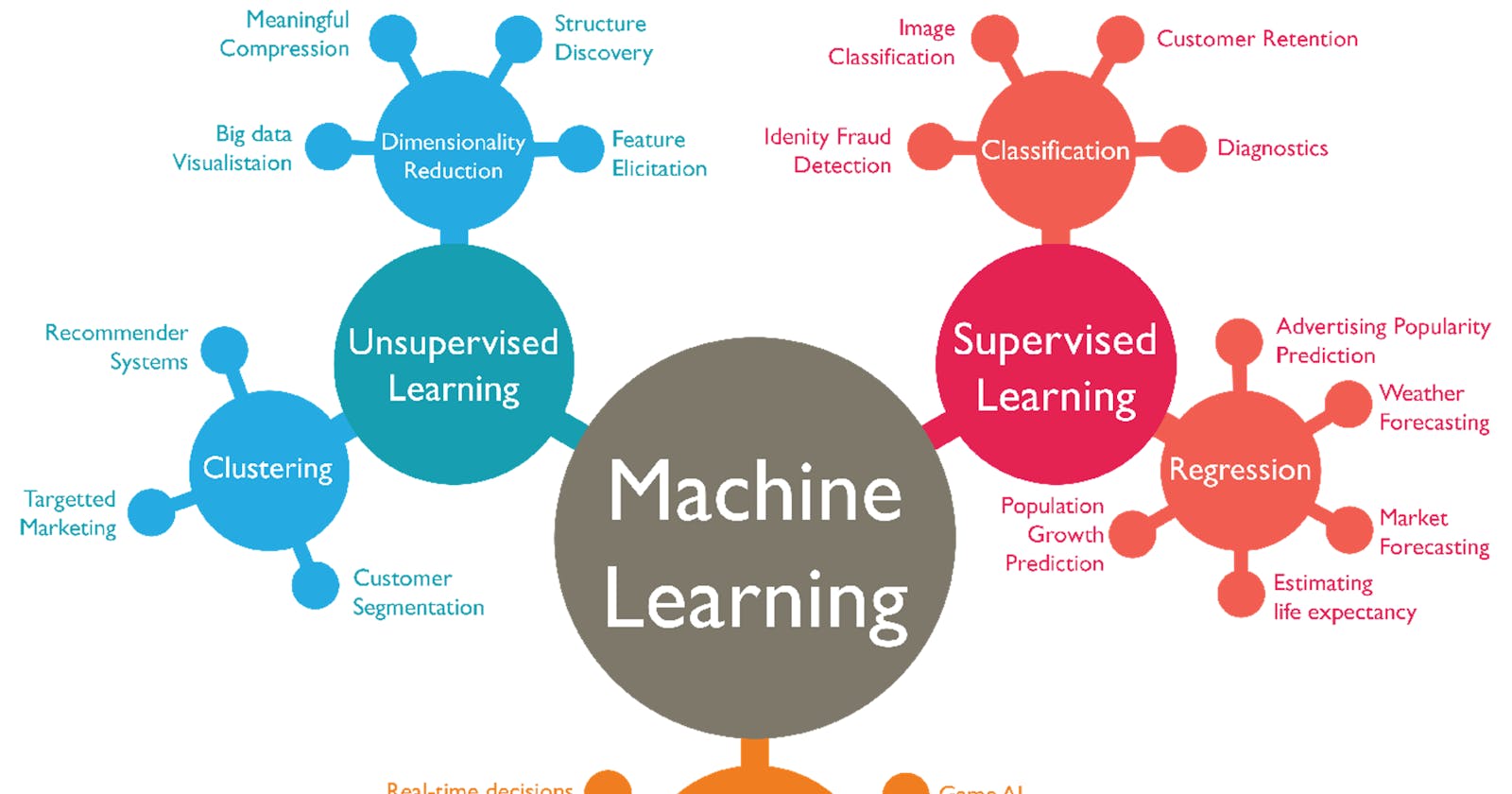


Supervised Learning Algorithms:
Supervised learning is a fundamental branch of machine learning where algorithms are trained on labeled data to make predictions or classifications.
Linear Regression: Regression (e.g. predicting house prices based on features like area, number of bedrooms).
Logistic Regression: Binary Classification (e.g. classifying whether an email is spam or not based on its content).
Decision Trees: Classification, Regression (e.g., predicting customer churn based on demographic and behavioral data).
Random Forests: Classification, Regression (e.g., predicting stock market trends based on historical data).
Support Vector Machines (SVM): Classification, Regression (e.g., classifying handwritten digits based on pixel values).
Naive Bayes: Classification (e.g. text classification, such as sentiment analysis or spam detection).
k-Nearest Neighbors (k-NN): Classification, Regression (e.g.. recommender systems, where similar users/items are recommended).
Gradient Boosting algorithms: (e.g., XGBoost, LightGBM): Classification, Regression (e.g. fraud detection, where the algorithm learns to identify fraudulent transactions).
Unsupervised Learning Algorithms:
Unsupervised learning is a branch of machine learning where algorithms analyze and explore data without labeled output. Instead of predicting specific outcomes, unsupervised learning algorithms aim to identify patterns, structures, or relationships within the data.
K-means Clustering: Clustering (e.g., segmenting customers into distinct groups based on their purchasing behavior).
Hierarchical Clustering: Clustering (e.g., organizing documents into a hierarchical structure based on their similarities).
DBSCAN(Density-Based Spatial Clustering of Applications with Noise): Clustering (e.g., identifying clusters of criminal activity in a city based on crime data).
Gaussian Mixture Models (GMM): Clustering (e.g., anomaly detection, identifying unusual patterns in data.
Principal Component Analysis (PCA): Dimensionality Reduction (e.g., reducing the dimensionality of image data while preserving its essential structure).
t-Distributed Stochastic Neighbor Embedding (t-SNE):Dimensionality Reduction (e.g., visualizing high-dimensional data in a lower-dimensional space).
Reinforcement Learning Algorithms:
Reinforcement Learning (RL) algorithms focus on training agents to make sequential decisions in an environment to maximize cumulative rewards. The agent interacts with the environment, takes actions, receives feedback (rewards), and learns from this experience.
Q-Learning: Sequential Decision Making (e.g., training an agent to play games like chess or Go).
Deep Q-Network (DQN): Sequential Decision Making (e.g., training an Al to play Atari games using a deep neural network).
Proximal Policy Optimization (PPO): Sequential Decision Making (e.g., optimizing robot locomotion or autonomous vehicle control).
Monte Carlo Tree Search (MCTS): Sequential Decision Making (e.g., playing games with high branching factors like AlphaGo).
Deep Learning Algorithms:
Deep Learning is a subset of machine learning that involves training artificial neural networks with multiple layers (deep architectures) to learn patterns and representations from data. These algorithms have demonstrated exceptional performance in various tasks and have revolutionized fields like computer vision, natural language processing, and speech recognition.
Convolutional Neural Networks (CNN): Image Recognition, Object Detection, Image Captioning (e.g., recognizing objects in images, detecting faces).
Recurrent Neural Networks (RNN): Natural Language Processing, Speech Recognition (e.g., language translation, sentiment analysis, speech-to-text conversion).
Long Short-Term Memory_(LSTM): Natural Language Processing, Speech Recognition (e.g., language modeling, named entity recognition, voice command recognition).
Generative Adversarial Networks (GAN): Image Generation, Image Editing (e.g., generating realistic images, creating deepfakes).
Transformer Networks: Natural Language Processing (e.g., machine translation, text summarization).
Semi-Supervised Learning Algorithms:
Semi-supervised learning is a type of machine learning where a model is trained using a combination of labeled and unlabeled data. This approach leverages the benefits of both supervised learning (using labeled data) and unsupervised learning (using unlabeled data) to improve the model's performance.
Expectation-Maximization (EM): Clustering (e.g., clustering unlabeled data using a mixture model).
Self-Training: Classification (e.g., expanding a small labeled dataset by using the model's predictions on unlabeled data).
Co-Training: Classification (e.g., using multiple views or sources of data to improve classification performance).
Ensemble Learning Algorithms:
Ensemble learning is a powerful machine learning technique that combines multiple models to improve overall performance and generalization. By aggregating the predictions of diverse models, ensemble methods can often achieve higher accuracy and robustness compared to individual models.
Bagging: (e.g., Random Forests): Classification, Regression (e.g., building a robust model by combining predictions from multiple decision trees).
Boosting: (e.g., AdaBoost, Gradient Boosting): Classification, Regression (e.g., sequentially building models to correct the errors made by previous models).
Stacking: Classification, Regression (e.g., combining predictions from multiple models using a meta-model).
Dimensionality Reduction Algorithms:
Dimensionality reduction is a set of techniques used to reduce the number of features or variables in a dataset while preserving its essential information. These algorithms are beneficial for visualizing high-dimensional data, reducing computation time, and improving the performance of machine learning models.
Principal Component Analysis (PCA): Dimensionality Reduction (e.g., reducing the dimensionality of high-dimensional data while preserving its essential structure).
Linear Discriminant Analysis (LDA): Dimensionality Reduction (e.g., maximizing the separation between classes while reducing dimensionality.
t-Distributed Stochastic Neighbor Embedding (t-SNE): Dimensionality Reduction (e.g., visualizing high-dimensional data in a lower-dimensional space).
Independent Component Analysis (ICA): Dimensionality Reduction (e.g., separating mixed signals into their original components).
Variational Autoencoders (VAE): Dimensionality Reduction, Generative Models (e.g. learning a compact representation of data, generating new samples).
Transfer Learning Algorithms:
Transfer learning is a machine learning technique that leverages knowledge gained from one task or domain to improve performance on another related task or domain. Instead of training a model from scratch, transfer learning adapts an existing pre-trained model by fine-tuning or using its learned features.
Pre-trained Deep Neural Networks: (e.g., ImageNet models): Classification, Object Detection (e.g., using pre-trained models on large datasets to extract features for a different task).
Fine-tuning: Classification, Object Detection (e.g., taking a pre-trained model and adapting it to a specific task with a smaller labeled dataset).
Domain Adaptation: Classification, Object Detection (e.g., applying a model trained on one domain to another related domain with limited labeled data).
Multi-task Learning: Training a model to perform multiple related tasks simultaneously, leveraging shared knowledge between tasks.